

Olena Pavliuk, Lviv Polytechnic National University, Lviv, Ukraine
Myroslav Mishchuk, Lviv Polytechnic National University, Lviv, Ukraine
Abstract. Due to the advancement and pervasiveness of wearable sensors, Human Activity Recognition (HAR) has lately become the focus of scientific study. HAR has applications in various fields, including sports, fall detection and prevention, anomalous activity detection, digital health and mobile medicine. Convolutional Neural Networks have become a popular approach for solving HAR problems due to their capability of automatical feature extraction and selection from the raw sensor readings. Nevertheless, this method requires massive training datasets to function well in various scenarios. This research presents a new Deep Learning model pre-trained on scalograms produced from the KU-HAR dataset. The raw sensor signals were preprocessed using the Continuous Wavelet Transform to improve the model’s performance. The optimal combination of Neural Network architecture and the transform parameters was selected by assessing 60 possible combinations. The suggested model was tested using the UCI-HAPT dataset to determine how it performs on new datasets of different sizes. The results indicate that usage of the pre-trained model, particularly with frozen layers, results in faster training, better performance, and smoother gradient descent on small datasets. In addition, the proposed model achieved a classification accuracy and an F1-score of 97.48% and 97.52%, respectively, on the KU-HAR dataset, which outperforms recent state-of-the-art studies where this dataset was used.
Introduction
Human Activity Recognition (HAR) attracts the attention of the scientific community due to its expanding role in areas such as sports, health care, epileptic seizure detection, abnormal activity recognition, military training, and fall prevention. The proliferation of intelligent wearable items, such as fitness bracelets, smartwatches, and smartphones, which typically contain various built-in sensors (gyroscopes, accelerometers, magnetometers, microphones, and GPS sensors), has made HAR particularly relevant.
Generally, the classical approach of HAR model construction includes such steps as signal preprocessing, feature extraction and feature selection, and the application of Machine Learning methods for activity classification. This approach has shown promising results in many studies; however, it has certain limitations. First, statistical signal characteristics are often deficient in distinguishing transitory states and complex, multi-step activities. Second, models constructed using the classical approach are frequently rather complicated. Third, this method necessitates the researcher’s high qualifications and an individualized methodology for each dataset.
Convolutional Neural Networks (CNNs) are a promising method for tackling HAR problems. Due to the automatical feature extraction and selection capability, CNNs are able to collect high-level signal characteristics and often perform better than models based on the classical approach. However, despite their established efficiency, CNNs require massive training datasets to produce satisfactory results on new data. There are various methods for mitigating this issue, like data augmentation and regularisation.
Significance of the study
A prospective approach to tackle underfitting and overfitting problems when using Deep Learning on small datasets is Transfer Learning (TL), in which a model trained on a source dataset is then fine-tuned on a target dataset. Currently, numerous models that are pre-trained on datasets for visual object detection are available (for example, ImageNet pre-trained models). However, this research aims to construct a pre-trained model targeted particularly for the HAR classification tasks. The proposed model will make it feasible to train a deep CNN on comparatively small HAR datasets by transferring knowledge from a much larger and broader source dataset.
Literature review
As for the Khulna University Human Activity Recognition (KU-HAR) dataset [1], authors of [1, 2] performed manual feature extraction and selection techniques in conjunction with the Random Forest classifier and achieved a classification accuracy of 89.67% and 89.5%, respectively, on this dataset. In [3], the authors used a Genetic Algorithm and Wavelet Packet Transform, followed by tree-based classifiers, yielding a maximum accuracy of 94.76%. Using a sequential CNN model and translating signal readings into circulant matrices, the authors of [4] obtained a classification accuracy of 96.67% on the KU-HAR dataset.
The University of California Irvine Human Activities and Postural Transitions (UCI-HAPT) dataset [5] was classified with promising results in works [6, 7]. In this study, however, we manually retrieved samples from the raw sensor data rather than using the provided frequency domain variables. The manual sample extraction was carried out due to the necessity of the Transfer Learning that source and target samples maintain the same shape. Using CWT and CNNs, the authors of [8] produced encouraging results for time-series classification problems.
Problem statement
This research aims to construct a pre-trained model targeted particularly for the HAR classification tasks. The KU-HAR dataset will be employed for preliminary model training, and the UCI-HAPT dataset will be used for the model fine-tuning and testing. The raw sensor signals will be preprocessed using the Continuous Wavelet Transform (CWT). Nine popular Neural Network architectures will be evaluated on eight sets of CWT-generated scalograms, resulting in a total of 60 combinations assessed. Each combination will be tested five times to avoid suboptimal local minima, resulting in more than 300 models being trained and evaluated. The chosen pre-trained model will be assessed with varying numbers of frozen layers to estimate how well it performs on various-sized target datasets that differ significantly from the source dataset.
The main part
The KU-HAR dataset was used for model pre-training and selection. It was released in 2021 and includes 20,750 non-overlapping time-domain samples belonging to 18 classes. Each sample consists of six channels and has a duration of 3 seconds. The recorded signals were collected from a triaxial gyroscope and triaxial accelerometer with a sampling frequency of 100 Hz.
The UCI-HAPT dataset and its subset were employed as a benchmark for the selected pre-trained model. It was published in 2014 and contains tri-axial accelerometer and gyroscope signals captured at a sample rate of 50 Hz using a smartphone. It includes sensor data for 12 classes, six of which are not included in the KU-HAR dataset. The signals were preprocessed using low-pass Butterworth and median filters.
One of the requirements of TL is that the source and the target datasets should have the same sample shape. To meet this requirement, firstly, the sampling frequency was increased from 50 Hz to 100 Hz. It was accomplished by inserting the mean value between two consecutive points. Secondly, samples were extracted from the preprocessed data using the non-overlapping windowing method with a 3-second sample duration, yielding 4847 six-channel samples.
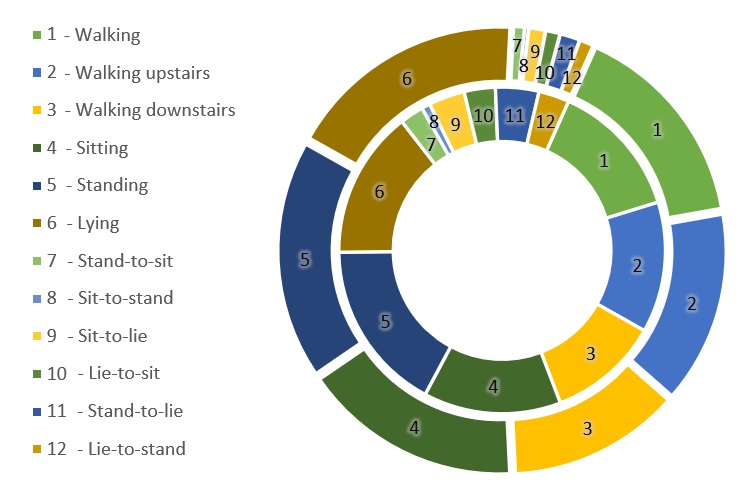
To assess the performance of the pre-trained model on various-sized target datasets, we employed the whole UCI-HAPT target dataset and its subset. The subset contains 30% of samples selected randomly from the whole dataset, which is 1652 samples. Figure 1 illustrates the target datasets’ distributions.
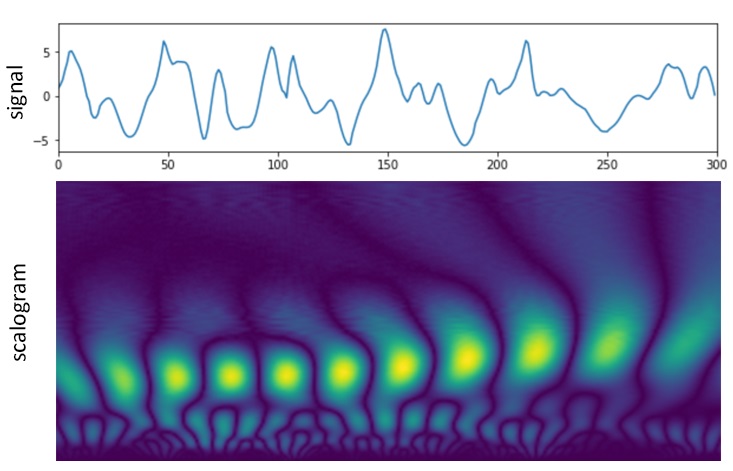
In this research, we employed CWT-generated scalograms to increase the models’ accuracy and reduce the possible overfitting and underfitting effects that often arise during model pre-training and fine-tuning. Scalograms with scale values from 0 up to 32, 64, 128, and 256 were produced using the Mexican Hat and Morlet wavelets. Thus, the performance of the models was tested using eight scalogram sets. An example of a transformed signal is illustrated in Figure 2.
To complete Transfer Learning, the top Fully Connected (FC) layer of the selected pre-trained model was substituted with a new one, with weights set using the Glorot initialization. The number of neurons in the new FC layer equals the number of activities in the target dataset (which is 12 for the UCI-HAPT dataset). The model’s performance was evaluated with various numbers of frozen (non-trainable) layers.
We tested nine Neural Networks architectures, including InceptionResNetV2, Xception, InceptionV3, ResNet50, ResNet101, ResNet152, DenseNet121, DenseNet169 and DenseNet201, on eight sets of CWT-generated scalograms. Each of the 60 combinations was attempted five times to prevent sub-optimal local minima, resulting in the training of 300 models. Classification accuracy was the criterion for model selection. It was found that the combination with the DenseNet121 architecture and the following transform configuration produced the best results: Morlet wavelet with a scale value from 0 to 256. This combination resulted in considerable classification accuracy and F1-score of 97.48% and 97.52%, respectively, on the KU-HAR source dataset. It is worth noting that the F1-score value, unaffected by dataset imbalance, is relatively close to the accuracy value, indicating the dependability of the selected model.
Given that KU-HAR is an imbalanced dataset with no conducted denoising operations, the performance of the suggested pre-trained model is rather promising. The classification results achieved on the KU-HAR dataset in other publications are compared in Table 1.
Table 1: Comparison of the results obtained on the KU-HAR dataset in recent publications.
| Publication | Classification accuracy (%) | F1-score (%) |
| [2] | 89.5 | 80.67 |
| [1] | 89.67 | 87.59 |
| [9] | – | 94.25 |
| [3] | 94.76 | 94.73 |
| [4] | 96.67 | 96.41 |
| Proposed | 97.48 | 97.52 |
As can be observed in Table 1, the proposed model outperforms the majority of state-of-the-art studies where the KU-HAR dataset was used, indicating the effectiveness of the selected model and the viability of the proposed method for the HAR classification problems.
To assess the pre-trained model’s performance on target datasets of various sizes, the whole UCI-HAPT dataset and its subset were employed. The subset includes 30% of the randomly chosen samples from the whole UCI-HAPT dataset. The model’s effectiveness was evaluated using the various number of frozen layers. The following configurations were considered: the first 308 layers are frozen, the first 136 layers are trainable, and all layers are trainable. The best results achieved by pre-trained and non-pre-trained models are compared in Table 2.
Table 2: Performance comparison of pre-trained and non-pre-trained models on the target datasets.
| Model | Whole UCI-HAPT dataset | UCI-HAPT subset | ||
| Accuracy (%) | F1(%) | Accuracy (%) | F1(%) | |
| Not pre-trained DenseNet121 | 92.23 | 92.19 | 86.29 | 86.38 |
| Pre-trained DenseNet121, only top layer trainable | 80.00 | 77.99 | 75.60 | 64.08 |
| Pre-trained DenseNet121, 308 layers frozen | 92.44 | 92.52 | 86.90 | 87.11 |
| Pre-trained DenseNet121, 136 layers frozen | 92.23 | 92.24 | 89.11 | 89.27 |
| Pre-trained DenseNet121, all layers trainable | 91.89 | 91.92 | 88.31 | 88.26 |
As can be observed in Table 2, the usage of pre-trained models resulted in superior results on both the whole target dataset and its subset. Regarding the whole UCI-HAPT dataset, the pre-trained model with 308 frozen layers achieved the highest classification accuracy and F1-score compared to the non-pre-trained model. For other configurations, however, pre-training did not result in a notable performance increase. It implies that the preprocessed UCI-HAPT dataset is sufficiently large for pre-training to potentially degrade the model’s performance, resulting in Negative Transfer.
Regarding the UCI-HAPT subset, all pre-trained models produced better results than the non-pre-trained model, except for the model with only the top FC-layer trainable. The model with 136 frozen layers produced the best results, increasing accuracy and F1-score by 2.82% and 2.89%, respectively. In addition, pre-training the models improved gradient descent and accelerated learning.
Conclusion
This paper proposes a new Deep-Learning model pre-trained on CWT-generated scalograms using the KU-HAR dataset. Nine Neural Network architectures were tested on eight scalogram sets, resulting in a total of 60 combinations being assessed. Each combination was tested five times to avoid suboptimal local minimums, resulting in more than 300 models being trained and evaluated.
It was determined that the model with the DenseNet121 architecture, Morlet wavelet, and scale value from 0 to 256 produced the best results on the KU-HAR source dataset, with a classification accuracy and F1-score of 97.48% and 97.52%, respectively, outperforming the majority of state-of-the-art works which employed this dataset.
The proposed pre-trained model was evaluated using the UCI-HAPT whole dataset and its subset to assess how it performs on various-sized target datasets with significant differences from the source dataset. The results indicate that usage of the suggested model increased accuracy and F1-score by 0.21% and 0.33% on the whole UCI-HAPT dataset, and by 2.82% and 2.89% on its subset, compared to the not pre-trained model.
It was determined that employing the pre-trained model, particularly with frozen layers, results in faster training, better performance and smoother gradient descent on small datasets. Nevertheless, using the suggested model on medium-sized and large-sized datasets might result in performance degradation.
In future research, it is intended to evaluate other combinations of CNN architectures and CWT configurations, as well as the impact of scale values on the models’ performance. In addition, a promising approach is a design of heterogeneous pre-trained models (for example, with the use of LSTM or GRU layers).
References
- N. Sikder, A.-A. Nahid, Ku-Har: An open dataset for heterogeneous human activity recognition, Pattern Recognition Letters 146 (2021) 46–54. doi:10.1016/j.patrec.2021.02.024.
- M.H. Abid, A.-A. Nahid, Two unorthodox aspects in handcrafted-feature extraction for human activity recognition datasets, 2021 International Conference on Electronics, Communications and Information Technology (ICECIT) (2021) 1-4. doi:10.1109/icecit54077.2021.9641197.
- M.H. Abid, A.-A. Nahid, M.R. Islam, M.A. Parvez Mahmud, Human activity recognition based on wavelet-based features along with feature prioritization, 2021 IEEE 6th International Conference on Computing, Communication and Automation (ICCCA) (2021) 933-939. doi:10.1109/iccca52192.2021.9666294.
- N. Sikder, M.A. Ahad, A.-A. Nahid, Human action recognition based on a sequential deep learning model, 2021 Joint 10th International Conference on Informatics, Electronics & Vision (ICIEV) and 2021 5th International Conference on Imaging, Vision & Pattern Recognition (IcIVPR) (2021) 1-7. doi:10.1109/icievicivpr52578.2021.9564234.
- J.-L. Reyes-Ortiz, L. Oneto, A. Ghio, A. Samá, D. Anguita, X. Parra, Human activity recognition on smartphones with awareness of basic activities and postural transitions, Artificial Neural Networks and Machine Learning – ICANN 2014 (2014) 177–184. doi:10.1007/978-3-319-11179-7_23.
- A.O. Jimale, M.H. Mohd Noor, Subject variability in sensor-based activity recognition, Journal of Ambient Intelligence and Humanized Computing (2021). doi:10.1007/s12652-021-03465-6.
- N.T. Hoai Thu, D.S. Han, Hihar: A hierarchical hybrid deep learning architecture for wearable sensor-based human activity recognition, IEEE Access 9 (2021) 145271–145281. doi:10.1109/access.2021.3122298.
- F.S. Butt, L. La Blunda, M.F. Wagner, J. Schäfer, I. Medina-Bulo, D. Gómez-Ullate, Fall detection from electrocardiogram (ECG) signals and classification by Deep Transfer Learning, Information 12 (2021) 63. doi:10.3390/info12020063.
- P. Kumar, S. Suresh, DeepTransHHAR: Inter-subjects heterogeneous activity recognition approach in the non-identical environment using wearable sensors, National Academy Science Letters 45 (2022) 317–323. doi:10.1007/s40009-022-01126-6.