

Nataliia Melnykova
Abstract
The paper proposes the development of an approach to modelling the nature of individual morbidity based on the Big Data approach. Analysis of large amounts of data requires the definition of groups of attributes that form functional dependencies. However, in real datasets obtained from different sources, important relationships are defined only for a subset of attribute group values. There are relationships, for example, between previously transmitted diseases and the nature of the disease now – such a relationship is established between subsets of values of different tuples and cannot be found in existing methods of searching for hidden data. The authors will call such dependences partial functional dependencies. Accordingly, the level of support for such dependencies is low, which does not allow to use them for further data analysis. At the same time, partial functional dependencies are modified associative rules, but they are executed only for a part of the data and depend on the time factor. The method of finding such dependencies will be based on the modification of the method of associative rules, which allows to reduce the time complexity and to use parallel and distributed mode for calculation.
Keywords: Big Data, associative rules, dependency analysis, Covid`19, partial functional dependencies
Introduction
It is a well-known fact that artificial intelligence really gives us many opportunities to understand and solve many complex problems in the practical and scientific space. The use of artificial intelligence can be useful primarily in systems that are designed to detect, track and predict disease outbreaks. The better we can track the spread of the virus, the more effective and faster we can fight it.
By analysing press reports, social networking platforms, and government documents, artificial intelligence can learn to detect outbreaks faster. It even turns out that such systems already exist and work, for example, the Canadian system for launching BlueDot [1]. The company’s software is designed to protect against the risk of pandemic outbreaks and protects lives by reducing the impact of infectious diseases that threaten human health. The developers claim that their software allows you to convey all the information about the threat of the COVID`19 epidemic within a few hours to the Centres for Disease Control and Prevention or the World Health Organization. The app also helps detect potentially infected people.
Artificial intelligence experts have used machine learning techniques to process online activity, news, health organizations’ reports and media activities to predict the spread of the outbreak in China. As well as the application of the Bayesian approach to predict the number of deaths in the future, using empirical data [5].
An important role is played by the problem of analysing the relationships between the individual characteristics of the patient and the characteristics of dynamics of changes in his condition during treatment and recovery.
The course of diseases, that caused by infections and viruses (even with known treatment prevention schemes) is influenced by various factors, namely [6,9]:
- variability of strains,
- nature of interaction,
- features of the distribution area: climatic conditions, development of infrastructure and connections, quality of medical care, chronic diseases inherent in this area, political situation, etc.
Materials and Methods
The peculiarity of medical data is their hierarchy and networking. Network data include information on comorbidities, allergic reactions, etc. These are the direct or indirect factor, which determines the nature of disease of the individual. Therefore, to find the hidden dependencies of the data and to determine the nature of the disease of the individual, it is necessary to find not only linear dependencies in the data.
The task of finding dependencies in the data requires the analysis of dependencies between dozens of parameters of the studied process and hundreds of possible sources of influence on this process. Dependencies are nondeterministic, and therefore modelling requires the use of statistical methods for analysing random processes. Often much of the information is hidden from observation or is not monitored. This introduces many difficulties in the process of analysing the collected information.
The modelling process requires data that can be obtained from known statistics, namely:
- the population of the districts of the region;
- the population density;
- the social distance between people;
- the disease duration;
- the probability of disease in human contact; mortality rate;
- the availability of crowded places (supermarkets, churches, pharmacies, markets, construction sites, gyms);
- the percentage of people who carry the disease asymptomatically;
- the presence of the procedure of isolation of sick people;
- the ability to move a person from the area to the regional centre and back;
- the incubation period
- and others.
The above factors can negatively affect the conduct, interpretation and generalization of research results, as well as the understanding and interpretation of the phenomenon under study. For stability of result, it is necessary to use ensembles of models, which are easy to parallelize.
The analysis of large amounts of data requires the definition of groups of attributes that form functional dependencies. However, in real data sets obtained from different sources, important relationships are defined only for a subset of attribute group values. For example, between previously transferred disease and the nature of the disease now – such a relationship is established between subsets of values of different tuples and cannot be found by existing hidden methods. We can call such dependences partial functional dependencies. Accordingly, the level of support for such dependencies is low, which does not allow to use them for further data analysis. At the same time, partial functional dependencies are modified associative rules, but they are executed only for a part of the data and depend on the time factor. The method of finding such dependencies will be based on the modification of associative rules. This reduces time complexity and uses parallel and distributed mode for calculation.
As part of the study of the problem, is necessary to:
- propose the development of already special methods of forming a training set of data and preprocessing of attributes, taking into account the specifics of the content of medical data and environmental data.
- develop an ensemble of data imputation models on the basis of basic models of various nature as a part of specialized information technology of recovery of the missed data for the automated processing of information.
- simulate different scenarios of influence by the state at the next stage of forecasting the dynamics of infection.
The formal model of the individual
Therefore, for a formal representation of the individual’s condition, the task of which is to find a personalized assessment and find solutions to improve it, it is necessary to build a formal model of the object, as a model of production expert system, which is usually used to solve this class of problems.
The knowledge base in accordance with the structural scheme of the system of personalized assessment is the selection of a set of rules R [7,12,14]:
![]() (1)
(1)
where the production of type
![]() (2)
(2)
The use of associative rules for study dependencies
The basic concepts in the theory of associative rules are subject set and transaction. A thematic set is a non-empty set of elements that can be part of a transaction:
![]() (3)
(3)
where ik – are the elements included in the subject sets, k = 1..n, n – is the number of elements of the set I.
The database has a certain set of transactions:
![]() (4)
(4)
where ti – is the corresponding transaction, m – is the total number of transactions.
The concepts of set and associative rule are closely related to another characteristic of an associative rule – trust, which is calculated as the ratio of a set that has both a condition and a consequence (in other words, support for an associative rule) to support a set that has only a condition.
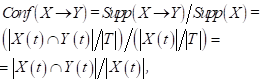 (5)
(5)
MinSupp and MinConf minimum support and validity thresholds are used to determine the significance of the rules, which are usually determined by experts based on their own experience:
![]() (6)
(6)
![]() (7)
(7)
Methods for finding associative rules find all associations that meet the constraints of support and confidence. However, this leads to the need to review a large number of associative rules, which it is desirable to reduce in such a way as to analyse only the most important of them.
Methods for finding associative rules find all associations that meet the constraints of support and confidence. However, this leads to the need to review a large number of associative rules, which it is desirable to reduce in such a way as to analyse only the most important of them.
Among the main algorithms for generating associative rules are AIS, SETM, Apriori, AprioriTid, AprioriHybrid [8]. The efficiency and feasibility of using each of them is determined by the structure and scope of the data set for which the search for associative rules, as the basis of these methods lies in the different principles of generation and selection of subject sets – candidates [13,15].
The proposed method
Based on the data analysis, information was collected about patients taking into account the parameters of the individual to determine the presence of diseases that are characterized as a priority.
Dataset is collected using google form https://docs.google.com/forms/d/1o8CMGVZv6BDkw-QIYg2F8VQzqcXxqklomRwXCLOZIcY, is funded by Central European Initiative and is verified by Lviv regional centre Covid`19 resistance. This dataset consists of the following characteristics:
- Age (categorical): 0-15, 16-22, 23-40, 41-65,>66
- Gender (categorical): male, female
- Region (string): Lviv (Ukraine), Chernivtsi (Ukraine), Belarus, Germany, Other
- Do you smoke (Boolean): yes, no
- Have you had COVID`19 (categorical): yes, no, maybe
- IgM level (numerical): [0..0.9) (negative), [0.9..1.1) (indefinite), >=1.1 (positive)
- IgG level (numerical): [0..0.9) (negative), [0.9..1.1) (indefinite), >=1.1 (positive)
- Blood group (numerical)
- Do you vaccinated influenza? (categorical): yes, no, maybe
- Do you vaccinated tuberculosis? (categorical): yes, no, maybe
- Have you had influenza this year? (categorical): yes, no, maybe
- Have you had tuberculosis this year? (categorical): yes, no, maybe
Taken into account 480 responses are presented in dataset.
Sample for training, consisting of states of 30 individuals. For data analysis, it was proposed:
- grouping of data by patient ID,
- separation of factors by patient ID,
- division into factors according to the patient’s condition,
- separation of factors according to the treatment scheme.
A three-step algorithm was used to recognize the patterns:
- creating a cluster of patients – to find the behavior of the condition,
- template construction – to find the sequence of state changes,
- next run ConditionType – to predict the next condition of the patient.
The cluster of the studied objects was created by means of R, factoextra packages (Fig. 1 shows the results of hierarchical clustering):
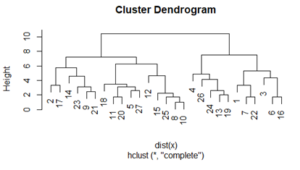
Fig. 1: Dendrogoram of hierarchical clustering
Random forest shows the better results. 500 trees are built.
OOB estimate of error rate: 16.61%

The biggest error is for class 1 (COVID’19 – yes). It can be explained by differences in IgG and IgM representation (data scatter is between 0.00 and 18.00) in different countries. The minimal depth values for all trees in a random forest is given on Fig. 2.
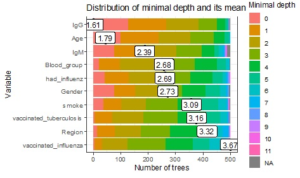
Fig. 2: Distribution of minimal depth of developed trees
Conclusion
An approach to modelling the nature of individual morbidity based on the Big Data approach is proposed. Analysis of large amounts of data requires the definition of groups of attributes that form functional dependencies.
Explained on real data sets obtained from different sources, important relationships are defined only for a subset of the values of the attribute group.
Dependencies with partial functional dependencies have a low level of support, which does not allow their use for further data analysis, and partial functional dependencies are modified associative rules, but they are executed only for part of the data and depend on the time factor.
A method of finding dependences is proposed, which is based on the modification of the method of associative rules, which allows to reduce the complexity of time and use parallel and distributed mode for calculation.
References
- https://root-nation.com/ua/articles-ua/tech-ua/ua-shtuchnij-intelekt-covid-19/
- https://qz.com/1803737/chinas-facial-recognition-tech-can-crack-masked-faces-amid-coronavirus/
- Perumal, Varalakshmi, et al. “Detection of COVID-19 Using CXR and CT Images Using Transfer Learning and Haralick Features.” Applied Intelligence, Aug. 2020. DOI.org (Crossref), doi:10.1007/s10489-020-01831-z.
- Chimmula, V. K. R., & Zhang, L. (2020). Time series forecasting of COVID-19 transmission in Canada using LSTM networks. Chaos, Solitons & Fractals, 135, 109864. https://doi.org/10.1016/j.chaos.2020.109864
- Bayes, C., Rosas, V. S. y., and Valdivieso, L., “Modelling death rates due to COVID-19: A Bayesian approach”, arXiv e-prints, 2020.
- Some Methods for classification and Analysis of Multivariate Observations”. Proceedings of 5th Berkeley Symposium on Mathematical Statistics and Probability. University of California Press. pp. 281–297 .
- Shakhovska, Natalya & Kaminskyy, R. & Zasoba, E. & Tsiutsiura, M.. (2018). Association rules mining in big data. International Journal of Computing. 17.25-32.
- The personalized approach to the processing and analysis of patients’ medical data. CEUR Workshop Proceedings. – 2018. – Vol. 2255:Proceedings of the 1st International workshop on informatics & Data-driven medicine (IDDM 2018) Lviv, Ukraine, November 28–30, 2018., 103-112
- Shakhovska, N., Fedushko, S., Greguš ml., M., Melnykova, N., Shvorob, I., & Syerov, Y. (2019b). Big Data analysis in development of personalized medical system. Procedia Computer Science, 160, 229–234. https://doi.org/10.1016/j.procs.2019.09.461
- Shakhovska, N., Fedushko, S., Greguš ml., M., Melnykova, N., Shvorob, I., & Syerov, Y. (2019b). Big Data analysis in development of personalized medical system. Procedia Computer Science, 160, 229–234. https://doi.org/10.1016/j.procs.2019.09.461
- Nataliya Boyko, Lesia Mochurad, Iryna Stetsiv, Yurii Kryvenchuk : Modeling of the Information System for Processing of a Large Distilled Data for the Investigation of Competitiveness of Enterprises // Proceedings of the 4th International Conference on Computational Linguistics and Intelligent Systems (COLINS 2020). Volume I: Main Conference Lviv, Ukraine, April 23-24, 2020. рр. 964-978
- Nataliya Boyko , Lesia Mochurad, Iryna Andrusiak, Yurii Drevnytskyi : Organizational and Legal Aspects of Managing the Process of Recognition of Objects in the Image // Proceedings of the International Workshop on Cyber Hygiene (CybHyg-2019) co-located with 1st International Conference on Cyber Hygiene and Conflict Management in Global Information Networks (CyberConf 2019), Kyiv, Ukraine, November 30, 2019. – 571-59
- Gaudart J, Ghassani M, Mintsa J, Waku J, Rachdi M, Doumbo OK, Demongeot J (2010) Demographic and spatial factors as causes of an epidemic spread, the copule approach: application to the retro-prediction of the black death epidemy of 1346. In: 2010 IEEE 24th International conference on advanced information networking and applications workshops (pp 751–758).
- .Huang C, Wang Y, Li X, Ren L, Zhao J, Hu Y, et al. Clinical features of patients infected with 2019 novel coronavirus in Wuhan, China. Lancet.(2020) 395:497–506. doi: 10.1016/S0140-6736(20)30183-5
- Pham QV, Nguyen DC, Hwang WJ, Pathirana PN. Artificial intelligence (AI) and big data for coronavirus (COVID-19) pandemic: a survey on the state-of-the-arts. Preprints. (2020) 2020:2020040383. doi: 20944/preprints202004.0383.v