

Melnykova Nataliia
Abstract
In the advent of large volumes of data, the use of artificial intelligence methods for processing heterogeneous data, in particular medical, is becoming increasingly relevant. The article investigate the methods of Data Mining and analyses the features and results of their application to the classification of patients’ states by the results of laboratory and other medical diagnostic methods. Particular attention is paid to naive Bayesian method, cluster analysis methods, in particular DBSCAN, PCA, and k-means, based on the identification of patients’ condition clusters and analysis of the correlation of distance between them and the search for the posterior maximum. The main advantages of application of the ensemble of methods for consolidation of large volumes of data, analysis of individual characteristics of the studied object and study of the process of its behaviour in the space of its states are determined.
Keywords: personalization, decision-making, medical data, artificial intelligence, Data Mining, Machine Learning
Introduction
The current state of hyperactive data growth is observed in any field of human activity, medicine is no exception. This situation encourages scientists to focus on finding optimization approaches to simplify the process of data consolidation, processing and analysis. To solve this class of problems, resort to methods of artificial intelligence, including Data Mining, Machine Learning. Today, physicians need the help of intelligent agents to make complex and valid decisions, which will help simplify the process of providing medical care to patients and ensure the reliability and objectivity of the results. Intellectual support of the processes of diagnosis, treatment or rehabilitation will ensure the quality of medical services. Research in the context of this article aims to evaluate clustering methods applied to medical data, especially data on patients with surgical pathology. This technique allows medical professionals to predict the development of the disease based on indicators of general condition during the treatment process, rehabilitation and more. To this end, the algorithms of naive Bayes, clustering, namely DBSCAN, PCA, and k-means were tested on medical data and evaluated using basic individual indicators of the sick person. The results of research show that the applied methods have a number of advantages and a number of disadvantages in the processing of medical data. [1,6,7,10].
Materials and Methods
Traditional ways for processing data
Specific features characterize medical data [3,5,8,12]:
- vagueness and sometimes inconsistency of terminology;
- a large number of qualitative features that subjectively assess the patient’s condition;
- lack of uniform algorithms for describing the patient’s condition, diagnostic and treatment processes;
- insufficient level of standardization of medical documentation;
- significant variability of medical data, small samples with unknown distribution laws, which significantly complicates statistical calculations and construction of appropriate estimates.
Some values can take values in a certain range, characterized by continuity, and the information they contain, is continuous or analogue. Continuous quantities are, for example, curves of changes in body weight, temperature, distance, and so on. Many quantities can only take integer values. Examples of discrete quantities: heart rate, number of patients in the department, etc., number of bed-days. Thus, despite the diversity of species, information is manifested in only two forms – continuous and discrete, but any continuous quantity with a certain degree of accuracy can be presented in discrete form [13,14,17].
Representing of the Processing Medical Data
To date, there are several approaches to building data models, namely [15,16,19].:
- statistical: based on theory and focused on testing hypotheses;
- based on machine learning: heuristic, focuses on improving the work of agents;
- computational: the integration of theory and heuristics, focused on a single process of data analysis, includes heuristics.
In cluster analysis, the detection of natural grouping in a data set is influenced by the choice of the correct degree of similarity or dissimilarity. The choice of the most appropriate factor is an open problem in cluster analysis. Different approaches to the inclusion of a non-Euclidean measure of difference for clustering are considered. Recently, analysts have been using distance-finding functions based on differences. A new measure of point-to-point distance is also proposed, and an algorithm is proposed that replaces the usual Euclidean distance. Its performance is compared with the classical k-means algorithm with Euclidean distance metrics and its functionally weighted variants using several synthetic data sets and current data of patients’ lives. Studies show that the results are useful, especially when the distribution of clusters is not regular [21,23].
The DBSCAN algorithm is used to search for clusters, where it checks the boundaries of each object. If an object boundary contains more points than the minimum number of objects, a new cluster with the root object is created. DBSCAN iteratively collects objects directly densely reachable from root objects, which can lead to the merging of several densely reachable clusters. The process terminates when no new object can be added to any cluster. Although, unlike partitioning methods, DBSCAN does not require you to specify the number of resulting clusters in advance, you will need to specify the values of the radius space parameters of any object and the minimum number of objects that directly affect the clustering result. The optimal values of these parameters are difficult to determine, especially for multidimensional data spaces [17,24, 26,28].
The k-means algorithm is simple, it minimizes distortion by distributing data between regions that do not intersect and are identified by their centres. The prevalence of the k-means method is due to its main advantages: simplicity, flexibility, fast convergence. But the k-means algorithm has a number of problems – it is necessary to know in advance the number of clusters, it is very sensitive to the choice of initial centres of clusters, and does not cope with the task when the object belongs to different clusters equally or does not belong to any.
NBA-based models are quite simple and extremely useful when working with very large data sets. For its simplicity, the NBA is capable of surpassing even some complex classification algorithms.
According to the results of use, we can outline the positive aspects of the algorithm are [2,18,20,22]:
- classification at the expense of NBA, including multiclass, is carried out easily and quickly;
- when the assumption of feature independence is met, the NBA outperforms other algorithms, such as logistic regression, and at the same time requires less training data;
- The NBA works better with categorical features than with continuous ones. For continuous signs, a normal distribution is assumed, which is a strong assumption.
The research results of medical data analysis
Thus, based on the analysis of existing clustering methods, their advantages and disadvantages are highlighted. In the proposed new approach to the processing of medical data of the patient there is a need to determine his condition at different stages of treatment, taking into account his individual characteristics and means of treatment at different stages[25,27,34]
This combines the advantages of the considered approaches to the improving k-means clustering methods. Where the solution is close to the global minimum obtained by sequentially running k-means for 1,2, …, k centroids. Significant acceleration of work is achieved by calculating the distances only to those centroids that have changed their location in the previous iteration, and reducing the number of candidate vectors. Taking into account the peculiarities of this method, we can analyze the behavior of the patient’s condition during treatment [30,33].
Bayes’ theorem allows us to calculate the a posteriori probability P (X | Y) based on P (X), P (Y) and P (Y | X). We assume that P (X | Y) is the a posteriori probability of a given class X (ie a given value of the target variable) at a given value of the feature Y, where X and Y are complex quantities that take into account the presence of n and m features characteristic of this state.
The number of conditions in the processing of medical data is determined by treatment protocols in accordance with the diagnosis. Then P (X) is the a priori probability of occurrence of this state;
P (Y | X) – plausibility, ie the probability of a given value of the features (a set of measures in this condition, namely, treatment, manipulation, medical laboratory tests, etc. in this condition in accordance with treatment protocols);
P (Y) – a priori probability of this value of the feature (complex of therapeutic measures).
Using Bayes’ theorem, we calculate the a posteriori probability for each class (state). The class with the highest a posteriori probability will be the result of the forecast. Therefore, we obtain the set of maximum a posteriori probabilities of each class, which are> 0.5.
Several important issues need to be addressed during the analysis, in particular:
- What similarity measures should be chosen to compare the subjects considered?
- How should clusters be formed?
- And what is the optimal number of clusters?
The similarity between objects is most often assessed by measuring the distance, and higher values (ie, large distances between cases) represent a large dissimilarity between entities.
Variables for describing patients in clusters included:
- gender (men or women),
- age (stratified as 18–30, 31-55, 56-70, 71-85,> 85 years),
- weight (stratified as 40-60, 61-80, 80-100,> 100 kg.),
- temperature (stratified as 35.6–36.9, 37-38, 38.1-39, 39.1-40, and> 40 (),
- pressure (stratified as 0-60, 61-90, 91-120, 121-140, 141-160, 161-180,> 180),
- manipulation,
- diagnostic tests,
- current diagnosis (currently being diagnosed),
- comorbidities the patient suffers from,
- results of bacteriological analysis,
- medication taken by the patient,
- the active substance of the drug,
- shared bed-day in the hospital during treatment
So according to the results of research, taking into account the parameters of 51 patients during hospitalization, can distinguish the optimal number of clusters. Taking into account the key patients’ parameters namely time-dependent and time-independent parameters of patients, the thermal map showed the proximity of the weight and sex attributes, as well as the substance and diagnosis. (Fig 1)
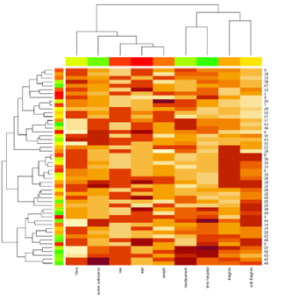
Fig 1. The thermal map showed the proximity parametrs.
In order to describe the relationships between them, it is advisable to analyze the criterion of divergence between patients. To do this, we enter the measure of distance Li. The distance not from one point – the etalon but the distance from the point aij (object presented for recognition) to all points of the set belonging to a given class is estimated.
Unequal attributes can have different ranges of represented entities in the selection, the distance can be very dependent on attributes with large ranges. Therefore, data are almost always normalized. This will normalize the values of patients with heterogeneity. To reconcile the data by calculating the average divided by the standard deviation, namely a biochemical blood, temperature data or bacteriological laboratory tests, etc.
Major clusters of elements for 1000,000 operations by k-means method were analyzed. (Fig.2)
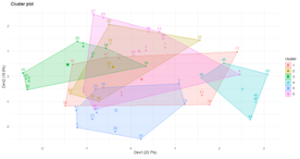
Fig.2 The applying the k-means method to determine the distribution of elements between 6
As a simple example of the fuzzy k-means algorithm, we will select a dataset of 51 individuals.
The optimal distance to the optimal parameter value can be used for each defined cluster. It is possible to determine the average distance from point aij to points of a training sequence belonging to :
![]() (1)
(1)
The classification procedure remains the same as when determining the distance to the etalon. The decision is made as .
Automation of data collection in hospitals will make the purpose of therapeutic treatment more accurate, will be able to effectively predict and prevent diseases. In this way, artificial intelligence will not only facilitate the work of doctors, but also help save more patients [9,24,26,29].
Conclusions
The study was conducted on the application of machine learning methods to find key clusters, taking into account the individual characteristics of patients, determining the distances between instances of the cluster.
Therefore, use the methods of artificial intelligence, it is proposed to classify individuals by condition, to determine the deviation of parameters from the normal parameters of the group, as well as the average parameters of this person. This allowed us to create a personalized approach to monitoring the condition, determining the number of clusters as a weighted sum confirmed health conditions, and providing recommendations for each patient based on long-term observation and monitoring under the guidance of a physician.
According to the results of the analysis, it becomes possible to predict the optimal general condition for a particular person, which will help to improve quality life satisfaction and ensure its continuation.
References
- Technology Research Reinvented/ https://www.venturescanner. com/page/91/
- Kayla Belcher, From $600 M to $6 Billion, Artificial Intelligence Systems Poised for Dramatic Market Expansion in Healthcare, Frost & Sullivan, 2020, https://ww2.frost.com/news/press-releases/600-m-6-billion-artificial-intelligence-systems-poised-dramatic-market-expansion-healthcare/
- Expanding our knowledge, finding new answers/ https://deepmind.com/about.
- Manage your health with Ada / https://ada.com/.
- Next Generation Solutions for Patient Engagement / https://www.sensely.com/
- Democratizing Data-Driven Medicine / https://www.sophiage-netics.com/home.html
- Oleksii Kharkovyna/ Artificial Intelligence & Deep Learning for Medical Diagnosis/ https://towardsdatascience.com/artificial-intelligence-deep-learning-for-medical-diagnosis-9561f7a4e5f.
- Waring J., et al. Automated Machine Learning: Review of the State-of-the-Art and Opportunities for Healthcare. Artificial Intelligence in Medicine, 104, Apr. 2020, 101822. DOI.org (Crossref), doi:10.1016/j.artmed.2020.101822.
- Kharkovyna O. Artificial Intelligence & Deep Learning for Medical Diagnosis, Nov 13, 2019, https://towardsdatascience.com/artificial-intelligence-deep-learning-for-medical-diagnosis-9561f7a4e5f/
- Ng, Man-Fai, et al. Predicting the State of Charge and Health of Batteries Using Data-Driven Machine Learning. Nature Machine Intelligence, 2( 3), 2020, 161–70.
- Godman, B.; Wettermark, B.; van Woerkom, M.; Fraeyman, J.; Alvarez-Madrazo, S.; Berg, C.; Bishop, I.; Bucsics, A.; Campbell, S.; Finlayson, A.E.; et al. Multiple policies to enhance prescribing efficiency for established medicines in Europe with a particular focus on demand-side measures: Findings and future implications. Front. Pharmacol. 2014, 5, 106.
- Artificial Intelligence in Medicine | Machine Learning. https://www.ibm.com/watson-health/learn/artificial-intelligence-medicine. Accessed 20 Apr. 2020.
- Democratizing Data-Driven Medicine / https://www.sophiage-netics.com/home.html Accessed 20 Apr. 2020.
- , Calvanese, G,. Giacomo D., Lembo M., Lenzerini A., Poggi, R. Rosati Calvan with using of fuzzy logic eseand. Ontology-based database access. In Proc. of SEBD–2007. 2007. 324–331
- Tkachenko, R., Izonin, I.: Model and Principles for the Implementation of Neural-Like Structures based on Geometric Data Transformations. In: Hu, Z.B., Petoukhov, S., (eds) Advances in Computer Science for Engineering and Education. ICCSEEA2018. Advances in Intelligent Systems and Computing. Springer, Cham, 754, 2019, 578-587,. https://doi.org/10.1007/978-3-319-91008-6_58
- Tkachenko R., Izonin I., Kryvinska K., Chopyak V., Lotoshynska N., Danylyuk D. Piecewise-linear Approach for Medical Insurance Costs Prediction using SGTM Neural-Like Structure. In: Shakhovska N., Montenegro S., Estève Ya., Subbotin S., Kryvinska N., Izonin I.:. (Eds.): Informatics & Data-Driven Medicine (IDDM 2018). Proceedings of the 1st International Workshop IDDM 2018. Lviv, Ukraine, November 28-30, 2018, .170-179, , CEUR-WS.org
- Tkachenko, I. Izonin, P. Vitynskyi, N. Lotoshynska, and O. Pavlyuk Development of the Non-Iterative Supervised Learning Predictor Based on the Ito Decomposition and SGTM Neural-Like Structure for Managing Medical Insurance Costs,” Data, 3 (4), 2018, 1-14
- Telenyk, S., Czajkowski, K., Bidiuk, P., & Zharikov, E. Method of Assessing the State of Monuments based on Fuzzy Logic. In 2019 10th IEEE International Conference on Intelligent Data Acquisition and Advanced Computing Systems: Technology and Applications (IDAACS), 1, 2019, 500-506. IEEE
- Dangare, C. S., & Apte, S. S. Improved study of heart disease prediction system using data mining classification techniques. International Journal of Computer Applications, 47(10), 2012, 44-48.
- Vijiyarani, S., & Sudha, S. Disease prediction in data mining technique–a survey. International Journal of Computer Applications & Information Technology, 2(1), 2013, 17-21.
- Tang, Y., Wang, Y., Cooper, K. M., & Li, L. Towards big data Bayesian network learning-an ensemble learning based approach. In 2014 IEEE International Congress on Big Data, 2014 ,. 355-357. IEEE.
- Mulesa P., Perova I. Fuzzy Spacial Extrapolation Method Using Manhattan Metrics for Tasks of Medical Data Mining. Proc. of 12th International Conference on Computer Science and Information Technologies CSIT’2015. Lviv, Ukraine., 2015, 104-106.
- Bodyanskiy Ye., Perova I., Vynokurova O., Izonin I. Adaptive Wavelet Diagnostic Neuro-Fuzzy System for Biomedical Tasks. Proc. of 14th International Conference on Advanced Trends in Radioelectronics, Telecommunications and Computer Engineering (TCSET), Lviv-Slavske, Ukraine, 2018, 20 – 24,
- Perova, O. Litovchenko, Ye. Bodyanskiy, Ye. Brazhnykova, I. Zavgorodnii, P. Mulesa. Medical Data-Stream Mining in the Area of Electromagnetic Radiation and Low Temperature Influence on Biological Objects. Proc. 2018 IEEE Second International Conference on Data Stream Mining & Processing (DSMP), August 21-25, 2018, Lviv, Ukraine, 3-6
- Perova I., Bodyanskiy Ye., Brazhnykova Ye., Mulesa P. Neural Network for Online Principal Component Analysis in Medical Data Mining Tasks IEEE First International Conference on System Analysis & Intelligent Computing (SAIC) 8-12 October 2018, Kyiv, Ukraine,.150-154
- Izonin, I. The combined use of the wiener polynomial and SVM for material classification task in medical implants production. International Journal of Intelligent Systems and Applications. 9,2018, 40-47
- Awwalu, J., Garba, A. G., Ghazvini, A., & Atuah, R. Artificial intelligence in personalized medicine application of AI algorithms in solving personalized medicine problems. International Journal of Computer Theory and Engineering, 7(6), 2015, 439.
- Melnykova, N., Shakhovska, N., & Sviridova, T. The personalized approach in a medical decentralized diagnostic and treatment. In 2017 14th International Conference The Experience of Designing and Application of CAD Systems in Microelectronics (CADSM), 2017, 295-297. IEEE..
- Ramprasanth, H., & Devi, A. Outlier Analysis of Medical Dataset Using Clustering Algorithms. Journal of Analysis and Computation ISSN:(0973-2861), 2019, 1-9.
- Bai, B. M., Nalini, B. M., & Majumdar, J. Analysis and detection of diabetes using data mining techniques—a big data application in health care. In Emerging Research in Computing, Information, Communication and Applications, 2019. 443-455. Springer, Singapore.
- Dudik, J. M., Kurosu, A., Coyle, J. L., & Sejdić, E. A comparative analysis of DBSCAN, K-means, and quadratic variation algorithms for automatic identification of swallows from swallowing accelerometry signals. Computers in biology and medicine, 59, 2015, 10-18.
- Cheng, D., Zhu, Q., Huang, J., Wu, Q., & Yang, L. A local cores-based hierarchical clustering algorithm for data sets with complex structures. Neural Computing and Applications, 31(11), 2019, 8051-8068.
- Ajayi, A., Oyedele, L., Delgado, J. M. D., Akanbi, L., Bilal, M., Akinade, O., & Olawale, O. Big data platform for health and safety accident prediction. World Journal of Science, Technology and Sustainable Development. 2019
- Martinez-Garcia, M., Zhang, Y., Wan, J., & Mcginty, J. Visually interpretable profile extraction with an autoencoder for health monitoring of industrial systems. In 2019 IEEE 4th International Conference on Advanced Robotics and Mechatronics (ICARM),2019, 649-654.