

Mykola Orlov, Lviv Polytechnic National University,
Andrii Pryshliak, Lviv Polytechnic National University, ORCID 0000-0003-1681-5178
Introduction
Definition of research issues
The issue of the research on “Infrastructure Scaling Strategies for Sportswear Business Development” concerns the development of effective infrastructure scaling strategies and methods used in sportswear to ensure successful business development.
Today’s global sportswear and equipment market is highly competitive. The demand for sportswear is constantly increasing, while consumers are becoming more demanding in terms of quality, availability and speed of service. To successfully compete in the market, sportswear businesses must have an efficient infrastructure that can scale and meet the needs of a growing business.
The problem is to find optimal strategies for scaling the infrastructure, which take into account the specifics of the field of sportswear. It is important to find out what factors affect the need to scale, such as demand growth, seasonality, geographical distribution of customers and logistics. The research also aims to identify different scaling strategies, such as vertical and horizontal scaling, use of cloud services and automatic scaling, and analyze their advantages and disadvantages in the context of sportswear.
The results of the study will help enterprises in the field of sportswear to develop optimal strategies for scaling infrastructure for the development of their business. This will allow them to effectively respond to growing demand, provide a reliable infrastructure for order processing, and fast delivery and meet customers’ needs.
In addition, research on scaling infrastructure for business development in the field of sportswear will also help identify best practices and determine recommendations for businesses in the field. Research can focus on analyzing cases of successful infrastructure scaling in the field of sportswear, studying the strategies and methods used by them, and identifying the factors that contribute to the success of these strategies.
Therefore, the problem of the research is the development and analysis of infrastructure scaling strategies for enterprises in the field of sportswear to ensure the effective development of their business. The study will identify the key factors influencing scaling, reveal the advantages and disadvantages of different scaling strategies, and provide recommendations for successful infrastructure scaling in the field.
The purpose of the work
The purpose of this work is to research and analyze infrastructure scaling strategies for sportswear business development and develop a deep understanding of the role and importance of infrastructure scaling strategies for sportswear business development. The main tasks of the research include the following:
- Theoretical Aspects of Infrastructure Scaling: Identify and understand key concepts, theories, and models related to infrastructure scaling in a business context.
- Analysis of the current state of the sportswear market: the study of development trends, the competitive situation, and the characteristics of consumers in the field of sportswear to determine the main challenges and needs for infrastructure scaling.
- Identification of factors affecting infrastructure scaling: analysis of demand, seasonality, geographic distribution of customers, logistics, and other factors affecting the need for infrastructure scaling in the field of sportswear.
- Different infrastructure scaling strategies: study vertical and horizontal scaling, use of cloud services, automatic scaling, and other approaches to determine their advantages and disadvantages in the context of sportswear.
- Determination of recommendations and best practices: development of recommendations for enterprises in the field of sportswear on effective scaling of their infrastructure, taking into account the obtained results of research and analysis.
The result of the research will be:
- Review of methods for assessing the current state of infrastructure in the field of sportswear: determination of available systems and resources, their scope, capacity, and efficiency.
- Study of factors affecting the need for scaling: analysis of demand, market growth rates, changes in consumer habits, seasonality of demand, and other factors that create the need for expansion and improvement of infrastructure.
- Analysis of different scaling strategies: overview and analysis of different approaches, such as vertical and horizontal scaling, use of cloud services, containerization, automatic scaling, etc.
- Evaluating the effectiveness of scaling strategies: analyzing the advantages, disadvantages, costs, risks, and impact of each strategy on business processes, logistics, and quality of service.
Development of recommendations: based on the research results, develop recommendations and best practices for enterprises in the field of sportswear regarding the selection and implementation of optimal infrastructure scaling strategies.
This work aims to bring into the field of sportswear recommendations for enterprises on optimal scaling of their infrastructure and ensuring successful business development. This will help sportswear businesses effectively respond to growing demand, ensure reliable and fast order processing, improve logistics, and meet the needs of their customers.
In addition, the work aims to expand understanding of infrastructure scaling strategies and their role in the context of business development in the field of sportswear. This includes an analysis of the various approaches, technologies, and tools used to scale infrastructure and their impact on business process efficiency, customer satisfaction, and enterprise competitiveness.
The ultimate goal of this paper is to provide specific recommendations and practical steps for sportswear businesses that wish to grow and develop, to use an infrastructure scaling strategy based on scientific knowledge and practical recommendations.
The relevance of the topic and its importance for the development of the field of sportswear
The relevance of the topic comes from several factors that influence the development of this field. The key aspects that highlight the importance of this topic for the development of the field of sportswear are described below:
- Growing Demand: Sportswear is one of the most dynamic industries in fashion and entertainment. In recent years, there has been a significant increase in the demand for sportswear, which is explained by the increased interest in an active lifestyle and sports. Providing high-quality sportswear that meets the needs of consumers is becoming an important factor in the success of businesses in this industry.
- Changes in consumer habits: Consumers are becoming increasingly demanding about the quality, style, and functionality of sportswear. They are looking for innovative technologies that improve comfort, and breathability of materials, and also allow them to achieve better sports results. Developing effective infrastructure scaling strategies will help businesses meet changing consumer needs and increase customer satisfaction.
- Competitive pressure: The sportswear market is highly competitive. It is home to big brands as well as new startups offering innovative solutions. To remain competitive, businesses need to develop scaling strategies.
A review of existing research
The concept of business infrastructure scaling and its role in business development.
Deciding on scaling
Douglas Squirrel, a CTO consultant who works with several scale-up companies, advises, “Often for technology-focused companies, the best time to invest is after you’ve proven your concept. When you know there’s a market and people who will buy your product, invest in infrastructure as much as you can.”
By building a scalable infrastructure that requires quick solutions, you the user put yourself in a strong position to avoid a situation where the infrastructure ceases to be functional, becoming increasingly costly and inefficient to use.
This isn’t always possible for cash-strapped startups that rely on rapid development to fuel growth, but the sooner you can rebuild and future-proof your infrastructure, the easier the scaling process will be.
Bill Packman, CEO of online investment company Nutmeg, agrees: “The decision to invest in infrastructure can be very difficult. We went through a thorough research process when we changed our back office operations in 2015. We went from a single vendor to a more complex combination of several different partners, but this change allowed us to move faster, scale more easily, and not limit our ambitions for growth.
Hiring the best technical talent
In a report by the ScaleUp Institute, 29% of leaders identified technical skills as one of the main areas of shortage of skilled personnel affecting their business, this is extremely close to management and business skills (respectively 30% and 34%).
The number of vacancies for highly qualified technical specialists at the moment exceeds the number of those who can create the required product. Top tech talent often has several job offers per month and can easily move on to the next employer.
So how to find the best technical engineers and as importantly keep them? One must begin by recognizing that the main motivation is not always about money or importance. Squirrel advises, “Frame your search in terms of the problems your business needs to solve so they can see how their input can help.”
Leading technicians are always looking for interesting challenges to test their skills, which helps the business to constantly innovate. If the product becomes uninteresting to the consumer or the company gets stuck, your best technical talent will likely want to move on to the next challenge.
The modern sportswear and equipment market is defined by advanced technologies, fashion trends and green practices. Technological innovations improve comfort and functionality, fashion and style become an integral part of a sports image, and environmental awareness leads to the creation of environmentally friendly products. The growing demand for sportswear and equipment opens up new opportunities for the development of the industry and meeting the needs of athletes and active people.
Attracting highly qualified personnel, constant improvement of technologies, and attentiveness to consumer needs will allow companies to successfully compete in the sportswear and equipment market and satisfy growing consumer demand. Companies must be ready to quickly introduce the latest technologies into their products, as well as provide stylish and environmentally friendly sportswear. It is important to know your target audience, understand their needs, and respond to current fashion trends.
A review of current trends in the field of sportswear and equipment allows you to see that this industry continues to develop and change under the influence of innovation, fashion, and environmental awareness. Fostering innovation, a creative approach to design, and green practices are key elements of success in the sports industry. Those companies that can adapt to changes, offer quality products, and meet the needs of the modern consumer will have a competitive advantage in the sportswear and equipment market.
The study of modern trends in the field of sportswear and equipment opens up wide opportunities for business development, increasing competitiveness, and satisfying consumer needs. Manufacturers must be ready to quickly adapt to changes, implement the latest technologies, and take into account fashion trends.
The ability of companies to adapt to modern trends and meet consumer demands is critical to success.
Definition of IT infrastructure
IT infrastructure refers to the set of hardware, software, and network resources necessary to ensure the functioning of information technologies in a specific organization or industry. It includes various components such as computers, servers, network equipment, software, databases, cloud resources and other technical solutions. IT infrastructure creates the basis for processing, storing, transmitting and analyzing information, which is an important resource for many areas of activity [1].
IT infrastructure components
IT infrastructure consists of various components that interact with each other to ensure the efficient operation of information technologies (Fig.1).
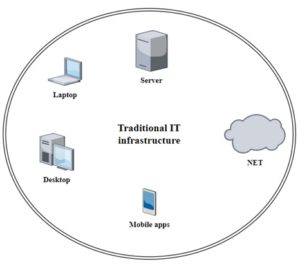
Figure 1. Traditional IT infrastructure
The main components of the IT infrastructure are:
- Hardware: These are physical components such as computers, servers, network equipment, disk devices, printers, etc. Hardware provides processing, storage, and transmission of information.
- Software: This is a set of programs and operating systems that manage hardware resources and perform the necessary functions. Software includes operating systems, add-ons, databases, data analysis programs, and other tools.
- Networking: These are components that provide communication between various devices and systems. Network facilities include routers, switches, cables, wireless access points, protocols, and other technologies for data transmission.
- Cloud Resources: Cloud resources are virtual computing power, data storage, and services provided over the Internet. They allow organizations to process and store data without having to own their physical equipment [2, p 24].
Impact of IT infrastructure
IT infrastructure has a significant impact on various aspects of modern society. It allows organizations to effectively perform their functions, helps to automate processes, improves communication and ensures access to information.
The main advantages of IT infrastructure:
- Improved productivity and efficiency: Information technology allows for the automation of many processes, reducing the human factor and errors. It helps organizations to efficiently perform work faster and reduce time and resource consumption. For example, with the help of automated production management systems, it is possible to ensure optimal planning, quality control, and speed of task execution.
- Improved communication and collaboration: IT infrastructure provides wide access to communication tools such as e-mail, instant messaging, video conferencing and collaborative work platforms. This helps improve communication between employees, customers and partners and facilitates collaborative work on projects regardless of geographic location.
- Ensuring access to information: IT infrastructure allows storing, processing and transferring large volumes of data. Thanks to this, organizations can provide quick and convenient access to a variety of information, which contributes to making better decisions and improving the level of service. For example, healthcare facilities may have access to patients’ electronic medical records, facilitating the coordination and delivery of healthcare services.
- Ensuring data security: Information protection is a critical aspect of IT infrastructure. Organizations must apply various protection methods, such as data encryption, backups, and physical and logical access to systems. Ensuring data security is essential to prevent unauthorized access, information theft and system failures.
- Support for innovation and development: IT infrastructure creates a base for the development of new technologies and innovations. It provides tools and resources for research, the development of new products and services, and the implementation of new ideas. IT infrastructure is the basis for the digital transformation of organizations and industries, which allows them to adapt to changes in society and the competitive environment [3].
IT infrastructure is an important component of modern society, which ensures the functioning of information technologies in various fields of activity. It consists of hardware and software, network facilities and cloud resources. IT infrastructure promotes productivity, communication, access to information, data security and innovation. Understanding its role and components will help to effectively use these technologies to achieve success in various fields of activity.
A comparison overview of GCP, AWS and Azure
Cloud computing services
The three largest providers of cloud services in this area are Amazon Web Service, Microsoft Azure, and Google Cloud Platform. When building an IT infrastructure, they can be relied on for high-quality services, including networking, computing, and storage. This section will contrast the three leading cloud service providers – AWS, Azure, and GCP.
The traditional method of hosting applications was extremely time-consuming. And required a lot of complex hardware and software resources to work. It also required a team of experts to install, configure, test, run, secure, and update them.
Therefore, the availability of “on-demand” computer resources, such as servers with RAM and a processor, known as “clouds”, appeared on the market [4, p.123-124]. Having block storage and object storage – and offering it as two different types of storage, databases, virtual networks, subnets, communication with local data centers, or in other words semi-structured, unstructured, and structured data. In this cooperative model, similar to your water or energy bill, you only pay for the resources you use when using the cloud [5, p. 308].
You can host your websites and web applications in a public cloud environment. If they contain non-public important information or personal data, there is an option to store the data in a private cloud environment. You can choose a hybrid cloud environment if you have a website and non-public information. So it can be concluded that you first need to choose a cloud deployment model (Fig.2) that will meet your organization’s needs, as each model addresses a distinct set of organization’s needs.
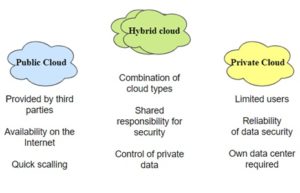
Figure 2. Cloud environments
Diagram of IaaS, PaaS, SaaS
The dynamic properties of cloud computing create the basis for new higher-level services (Fig.3). These services can complement and often provide necessary services for Agile and DevOps teams [6, p. 272-284].
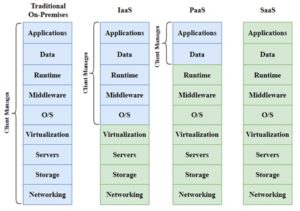
Figure 3. Comparison of cloud computing services
Infrastructure as a Service (IaaS) is the basic level of a cloud service that allows organizations to rent IT infrastructure – servers, data storage, networks, operating systems – from a cloud service provider. IaaS allows users to reserve and allocate the resources they need from physical server warehouses. In addition, IaaS allows users to reserve pre-configured machines for specialized tasks such as load balancers, databases, mail servers, and distributed queues.
DevOps teams can use IaaS as a core platform for building a DevOps toolchain, which can include the use of various third-party tools.
Platform as a Service (PaaS) Platform as a Service (PaaS) is a cloud infrastructure built on top of IaaS that provides resources for building user-level tools and applications. It provides the underlying infrastructure, including computing, networking, and storage resources, as well as development tools, database management systems, and middleware.
PaaS uses IaaS to automatically allocate the resources needed to support a technology stack based on a specific programming language. Popular programming language technology stacks include Ruby On Rails, Java Spring MVC, MEAN, and JAM. PaaS users can simply upload an artifact of their additional code, which will be automatically deployed on the PaaS infrastructure. It is an innovative and powerful workflow that allows teams to fully focus on developing their business application code without worrying about hosting and infrastructure issues. PaaS automatically manages scaling and infrastructure monitoring to increase or decrease resources based on traffic load.
Software as a Service (SaaS) delivers software applications over the Internet, on-demand and usually by subscription. Cloud providers host and manage the software, providing software updates and security patches as needed. Examples of SaaS are customer relationship management (CRM) systems, web-based email applications, productivity tools such as Jira and Confluence, analytics tools, monitoring tools, chat applications, and more (Fig.4) [7].
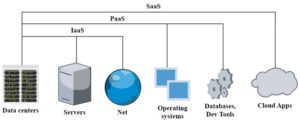
Figure 4. Application of Iaas, PaaS and SaaS
AWS, Azure, and GCP comparison results.
Amazon Web Services (AWS) is the most complete and widely used cloud platform in the world. It provides on-demand cloud computing services to individuals, companies and government organizations on a subscription basis.
AWS has more than 200+ services in its arsenal. It has more than 99 availability zones in 31 regions. The platform is designed with a combination of infrastructure as a service (IaaS), platform as a service (PaaS), and packaged software as a service (SaaS). AWS provides a wide range of services that are used by many famous companies such as Netflix, BBC, Facebook, Spotify, and LinkedIn.
Microsoft offers Azure as a cloud computing service. A collection of individual cloud computing services, including variations of Microsoft’s proprietary technologies, are used to build, test, deploy, and manage cloud applications.
Azure Has almost 200+ services. It has 78 regions available in 140 countries, far more than other cloud service providers. Some well-known brands such as Adobe, HP, eBay, Samsung and Rolls-Royce use Azure.
Google Cloud Platform offers a set of cloud computing services needed to build, deploy, scale, manage, and operate a cloud. These services are identical to those used to run Google products, including Google Search, Gmail, YouTube, and Google Drive.
Google Cloud Platform (GCP) operates about a hundred active services, GCP offers 35 regions and 106 work zones. PayPal, Twitter, Airbus, and Toyota have chosen Google’s cloud platform (Fig.5).
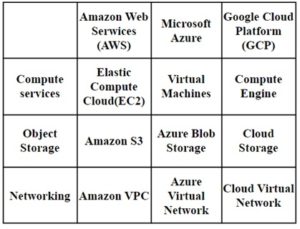
Figure 5. AWS, Azure, and GCP comparison
Infrastructure scaling strategies
Overview of vertical scaling and horizontal scaling strategies
What is scalability?
Before looking at the vertical versus horizontal scaling debate, it is important to understand what scalability is. An application’s scalability is a measure of the number of client requests it can handle simultaneously. When a hardware resource is exhausted and can no longer handle requests, this is considered the limit of scalability. When this resource limit is reached, the application can no longer process additional requests. To efficiently handle additional requests, administrators must scale the infrastructure by adding more resources such as RAM, CPU, storage, network devices, etc [8, p.108-112]. Vertical and horizontal scaling are two methods used by administrators for capacity planning.
Scalability is an important requirement of a cloud environment. You need to dynamically scale up or down the size of IT to meet changing IT business needs and manage unexpected spikes in traffic. This will reduce latency and improve performance by preventing interruptions [9, p. 512].
What is horizontal scaling?
Horizontal scaling (Fig.6) is an approach that involves adding additional devices to the infrastructure to increase capacity and efficiently handle growing traffic demands [10, p. 204]. Horizontal Scaling consists of expanding capacity horizontally with additional servers, in . Load and processing power is distributed among multiple servers in the system using a load balancer. This approach is also called “scaling out” [11, p.368].
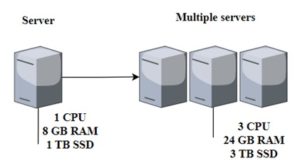
Figure 6. Horizontal scaling
What is vertical scaling?
Scaling up is a type of scalability in which more computing and processing power is added to a machine to improve its performance. This approach, also called the English analog of vertical scaling (Fig.7), allows you to increase the capacity of the machine, keeping resources within the same logical block. In this approach, the power of the processor, memory, hard disk, or network increases. An illustrative example would be purchasing an expensive machine such as VMware ESXi as a bare-metal hypervisor.
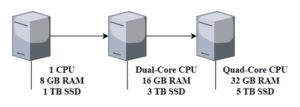
Figure 7.Vertical scaling
The difference between vertical and horizontal scaling is how the hardware characteristics of the device are improved to achieve scalability. In the vertical scaling model, the server hardware configuration increases without changing the logical unit. In a scale-out model, the number of instances increases without increasing hardware performance. In other words, horizontal scaling means adding more machines, and vertical scaling means adding more capacity.
Another difference is that in horizontal scaling, a sequential piece of logic is broken up into smaller pieces and executed in parallel on multiple devices. Administrators distribute tasks across machines in a network using patterns such as MapReduce, Tuple Spaces, and more. MongoDB, Cassandra and other methods are used for data management [12, p.552].
In the case of vertical scaling, the logic remains unchanged. The same code is executed on a larger machine. Multithreading is used for simultaneous programming, which is performed on many cores of the device’s processor. Amazon RDS and MySQL are commonly used for this process.
Advantages and disadvantages of Vertical and Horizontal scaling
Both solutions – either vertical or horizontal scaling – have their advantages and disadvantages. The advantages of vertical scaling are that it does not change the logic and is easy to implement and manage. Data is stored on one node and executed on many cores, which simplifies work. With shared address spaces, data and messages can be easily and efficiently shared by transferring links. Reducing the physical area of the solution also results in lower power and cooling costs. At the same time, the software is cost-effective, and single-device management for IT administration becomes simple.
The disadvantage of vertical scaling is the presence of an upper limit of scalability. It is possible to upgrade a device to a certain configuration, and after that the upgrade options are limited. Scaling up is disruptive because you have to shut down the device and move the application to a more powerful machine. A single device can become a single point of failure.
Horizontal scaling, on the other hand, allows for greater flexibility and high scalability. You can add many instances to handle increased load and improve performance. No upper limit on scalability allows more flexibility for growth. Horizontal scaling is also more reliable because there are many instances, and if one of them fails, the system continues to work. Horizontal scaling can also be more cost-effective, as less powerful hardware can be used.
However, horizontal scaling can be more difficult to implement and manage. It is necessary to solve the issue of load distribution between different instances and ensure data synchronization and data storage in a distributed system. Also, the cost of supporting and managing many machines can be higher [20].
Therefore, each type of scaling has its advantages and disadvantages, and their choice depends on the specific requirements, constraints, and characteristics of the project or system.
When it comes to horizontal scaling, the capacity of an individual machine doesn’t matter. You can instantly add as many devices as you need without any interruptions. This increases reliability. It is possible to distribute application instances on different systems and easily perform parallel calculations. However, the data is shared and executed on different devices. Since data is shared between multiple nodes without a common address space, it becomes a challenge to share and process data, as you need to reference the data or create copies of the data [13, p. 201-204].
Vertical vs. Horizontal Scaling: How to Choose?
When it comes to vertical versus horizontal scaling (Fig.9), the difficulty arises in choosing which model to choose. Here are some possible arguments:
- Take into account your application (decision): If the business is aimed at a global audience and there is a need to deliver applications in different geographical regions, to effectively manage geo-latency, reliability and failures, horizontal scaling will be the right choice. It will also help address local regulatory compliance issues.
- Need to balance cost and performance. When scaling up, there is no flexibility to choose optimal configurations for specific loads dynamically. The strength of the configuration will limit system performance. When scaling up, you can choose a configuration to improve performance and optimize costs. However, it is important to check whether a single device can handle such a load. In this case, it is beneficial to add more power instead of using multiple machines for the same purpose.
- Duplication management When scaling up, there is a single device binding that results in a single point of failure. However, when scaling up, built-in reliability will be available. However, one must consider the costs of operating one device compared to many.
- The best of both worlds In some cases, you don’t need to adhere to a specific scaling model. For example, if distributed storage systems are used in a data center, you can switch between distributed systems and a single disk engine. In such cases, you can try both vertical and horizontal scaling models to easily switch between them. However, to make this transition, your application must be designed with decoupled services so that some layers can scale up and others scale horizontally [18].
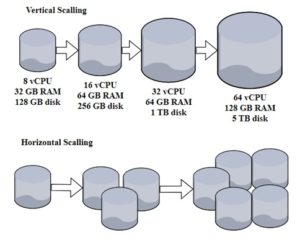
Figure 8. Vertical and horizontal scaling structure differences
How to implement vertical scaling based on the AWS cloud service.
Manually scaling resources on AWS is quite simple. To vertically scale a resource, you need to change the instance size. For example, if you are using a t2.medium instance, you can change it to a t2.large instance. Similarly, scaling down is reducing the instance size to t2.small, t2.micro, t2.nano, etc. The advantage is that no scaling rules need to be defined. However, you will have to face a short period of downtime [14, p. 55].
Automatic vertical scaling on AWS is not standard. Previously, AWS did not offer automatic vertical scaling. This caused downtime when the new instance had to be moved to a new machine or restarted on a more powerful machine. AWS now offers a workaround for automatic vertical scaling. AWS Ops Automator is an AWS tool that helps manage your AWS infrastructure. With AWS Ops Automator V2, AWS introduces vertical scaling. It automatically adjusts the capacity of the resource with the lowest costs.
How does it work?
Here are the steps to set up vertical scaling on AWS(Fig.9):
1. The user defines an event or time for the scaling event to trigger.
2. The user chooses whether to reconfigure or resize the instance.
3. Amazon CloudWatch monitors the traffic load and triggers a scaling task based on a predefined time or event.
4. AWS Lambda starts the scaling process. Depending on your selection, it scales the instance up or down, terminates the original instance, and launches new instances to suit the scaling requirements [15, p. 113-114].
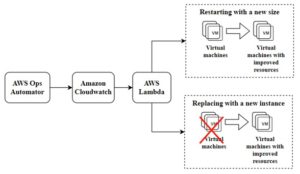
Figure 9. Vertical scaling on AWS
How to implement horizontal scaling on AWS?
Horizontal scaling adds additional nodes or machines to your infrastructure to handle new load demands. This adds some complexity to the overall design but has numerous benefits such as:
Reduced downtime – no need to shut down the old machine when scaling as a new machine is being added. As a result, total downtime is reduced. Improved Availability and Resilience – Relying on a single machine for all your data and operations puts you at great risk of losing everything when that machine fails. Spreading the load across multiple nodes avoids this risk. Increased performance – Horizontal scaling allows you to delegate traffic to more endpoints for connections, which takes the load off the main server [16, p. 280].
Next, the services that AWS provides for horizontal scaling will be considered:
Adding AWS ELB (Elastic Load Balancer) is an AWS service that allows you to distribute the load between your EC2 instances or Lambda functions. The most common type of ELB is an application or “application load balancer” suitable for HTTP/HTTPS traffic. It only takes a few minutes to set up and load balance between your EC2 instances, lambda functions, or even Docker containers. It supports the following AWS services:
EC2, Fargate, ECS (Elastic Container Service), EKS (Elastic Kubernetes Service) instances.
Automatic scaling/dynamic scaling (auto-scaling). AWS automatically increases or decreases capacity based on load or other metrics. For example, if memory usage exceeds 90%, Amazon EC2 Auto Scaling can dynamically add a new instance. As soon as the load decreases to a normal level, the total power will return to its original position, for example, to one node.
Auto-scaling isn’t just based on health metrics; it is possible to adjust scaling according to a specific schedule. For example, if you expect a heavy user load on Black Friday, you can set up scheduled scaling so that the system scales during a specified schedule and then returns to its original capacity when the schedule ends. Scaling based on exact date and time is also a common example of scheduled scaling [17. p. 352].
When do you need automation?
For example, there is a situation where you need to perform rapid deployments in a very dynamic environment many times a day. Doing this manually is not only time-consuming but also error-prone. This applies not only to deployment but also to infrastructure in general. Manually running 200 servers is inconvenient and inefficient. Automation is the solution to all these challenges, be it deployment, infrastructure management, environment replication, and more. The more processes are automated, the more scalable and less error-prone they become. Next, the main areas where automation should be applied to achieve scalability will be discussed.
An example of AWS infrastructure for Serverless web hosting on AWS app runner (Fig. 10).
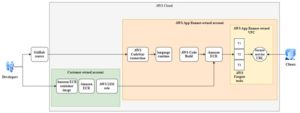
Figure 10. Serverless web hosting on AWS app runner
Iterative deployments (development flows, CI/CD) Modern systems make extensive use of continuous integration (CI) and continuous deployment (CD). In large projects, many developers work on one project.
Continuous integration ensures that any code conflicts or system failures are detected almost immediately. CI allows you to fix any problems with the code sooner rather than later.
Continuous Deployment (CD) is an integral part of scalable systems developed using the Agile methodology. It ensures that a system is in place that can be deployed, tested, and evaluated by stakeholders, or at least ready for quality testing. This is what development streams are for. Many cloud providers have built-in CI/CD capabilities. You can automatically build and deploy an assembly as soon as the code is uploaded to the repository. The complete ecosystem also includes automated testing to ensure that all tests for a newly created build pass.
In this context, some of the AWS services are CodePipeline, CodeBuild, CodeDeploy, etc.
Replication of environments (containerization) Containers isolate code from the environment on which it must run. For example, there is a team of 50 developers. For example, each of them must manually configure the development environment of the same project. In this case, it will take time and effort and will require technical oversight to ensure that all developers configure their environment correctly and on time. Docker containers solve this problem. All developers need is just one Docker file/image, and it takes just a few minutes to set up a similarly complex environment [19].
AWS provides fully managed services for containerization, including ECS, EKS, Beanstalk with multi-container support, and more.
Automated testing when there are only 2 developers on a small project, testing builds is easier and more manageable. The same program grows to 250 developers and dozens of complex modules. Adding more QA team members to the project is a linear and not practical approach. Take Facebook for example, where more than 50,000 builds are created every day just for the Android platform. No amount of manual testing will help in this case.
Automated testing is the solution to this problem. Once integrated with CI/CD, you can run automated tests on the build and it will notify the user if the build passes all tests. If any of the tests fail, you can also configure an automatic build rollback.
One notable AWS service that helps in test automation is AWS Device Farm. However, the most common tools used in automated testing include Jenkins, Selenium, and others.
Infrastructure Automation As an application grows and becomes more complex, so must its infrastructure. Replication of the same infrastructure has always been a manual operation before it became possible to see “Infrastructure as Code” (Infrastructure as Code, IaC). With the help of simple text files, you can configure all the infrastructure needs of the consumer, whether it is a database, container services, message queues, etc. Everything can be created automatically based on the chosen configuration. With this technique, it is possible to easily and quickly clone and replicate hundreds of servers.
For infrastructure automation, CloudFormation is an excellent service from AWS.
Scaling Database (Amazon RDS) Amazon Relational Database Service (RDS) is Amazon’s “Database as a Service” database service. It supports all major relational database management systems. It provides many features that make your database scalable. Features of some of them are as follows:
Using Multi-AZ RDS Multi-AZ is an RDS feature that places a redundant database in another available zone to provide high availability and fault tolerance. You only need to activate this function in the RDS control panel. Both the primary database and the backup database will be synchronized in real-time. If the primary database fails, all requests to the primary database will automatically be redirected to the standby database without any changes.
A standby database cannot be used to reduce the load on the user database. It is intended only to failover to a backup database. If there is a need to distribute the load between RDS databases, the Amazon RDS Read Replicas feature is required.
Using Amazon RDS Read Replicas Read Replicas are a secondary server that is an exact copy of the primary database server. Similar to Multi-AZ, both primary and secondary databases are automatically synchronized in real-time. However, you can direct application traffic to the Read Replicas instance to reduce the load on the primary database. Typically, read replicas are placed in another available zone for high availability.
If the primary database goes down, you can elevate the read replica to the primary database role. Read replicas are primarily used to distribute read-only requests to a read replica instance.
When to use Aurora Amazon Aurora? It is a MySQL and PostgreSQL-compatible relational database designed for AWS that combines the performance and availability of traditional enterprise databases with the simplicity and cost-effectiveness of open databases. Compared to RDS, Aurora has built-in high availability, backup, etc. If the user is migrating from commercial databases such as Oracle or SQL Server, they should choose Aurora because it will provide the same performance at a lower price. If the workload is light to medium and a limited number of concurrent database connections are required, RDS should be the preferred choice over Aurora.
Promoting Weak Coupling
Highly scalable systems are characterized by weak coupling between components. Tight coupling is one of the biggest obstacles to scaling systems. One of the best ways to reduce communication is to use message queues, functions as a service (Lambda), cloud search, etc. Next, we will consider how these tools can be used to scale systems.
SQS Amazon Simple Queue Service (SQS) is used to build highly reliable and scalable distributed systems. If system A wants to send a message to system B, these two systems depend on each other, resulting in a tight coupling. Increasing the number of interdependent systems reduces ability to scale. Adding a queue between these systems decouples this architecture in the simplest terms and increases scalability. Installing and managing SQS queues requires no additional administrative effort. SQS queues are dynamically created and scaled automatically so you can build and develop your applications quickly and efficiently. One of the most efficient ways to use SQS is to use batching in SQS [20].
Lambda AWS Lambda belongs to AWS’ Function as a Service. It is the best choice when building a serverless architecture. Lambda is a powerful tool that allows you to build scalable applications without worrying about hardware.
It is best suited for any server-side processing, be it document conversion, log analysis, external API integration, etc. Lambda automatically scales up and down as needed, so it’s also ideal for unpredictable workloads.
Implementing Elasticache to scale applications. Caching is an integral part of any enterprise application, especially web and mobile applications. As the application grows, it is important to maintain high performance in terms of response time and improve the user experience. Making a network query to the database for data every time it is called results in technical debt. Adding a cache can reduce application response time, reduce database load, and improve the ability to scale. AWS provides a managed service called Elasticache, where there is an option to use Redis or Memcached depending on the needs of the users. Redis can also be used in cluster mode, where caching can be managed across multiple nodes for increased availability and fault tolerance.
Using a CDN to Scale Content Amazon CloudFront is a CDN (content delivery network) that delivers content closer to the user’s geographic location. Using Amazon CloudFront and its distributed locations as part of the solution architecture allows applications to quickly and reliably scale globally without adding complexity to the solution. CloudFront is an integral part of the architecture if users are geographically distributed. Some of CloudFront’s best use cases include delivering static web content, replacing S3 for global users, streaming video, and more.
In summary, scalability is an important component of enterprise software development. It helps businesses grow quickly, resulting in lower maintenance costs, better user experience, and greater flexibility.
Factors to consider when scaling include costs, projected growth, technical needs, compliance requirements, traffic/content type, etc.AWS provides many services to achieve scalability, including Elastic Load Balancer, RDS read replicas, Elasticache, Elastic Container Service (ECS), CloudFormation, CI/CD services, ECR, EKS, SQS, Lambda, and others. Businesses can use a combination of these services to achieve the desired level of scalability.
6 groups of AWS Well-Architected Framework
Creating a software system is similar to building a building. If the foundation is not strong, structural problems can undermine the integrity and functionality of the building.
When building technology solutions on the Amazon Web Services (AWS) platform, if you don’t pay attention to the six pillars of operational differentiation, security, reliability, performance efficiency, cost optimization, and sustainability, it can be difficult to build a system that meets expectations and user requirements.
Adding these pillars to the consumer architecture helps create stable and efficient systems. This allows you to focus on other aspects of the design, such as functional requirements [21].
The AWS Well-Architected framework helps cloud architects build the safest, most productive, most reliable, and most efficient infrastructure for their applications. This framework provides a consistent approach for evaluating AWS customer and partner architectures and guides implementing designs that can scale as your application needs grow over time.
This post provides an overview of the six pillars of the Well-Architected framework and explores design principles and best practices.
Operational Excellence The concept of operational excellence includes the ability to support the efficient design and operation of workloads, gain insight into their performance, and continuously improve processes and procedures that support the creation of business value. You can find practical implementation recommendations in the document “The column of operational difference”.
Principles of design
There are five design principles for achieving operational differentiation in the cloud:
- Execution of the operation as code
- Making frequent small and reversible changes
- Improvement of the procedure of operations
- Anticipation of failure
- Training based on all cases of failed operations
Best Practices: Operations teams must understand their business and customer needs to support business results. The operations department creates and uses procedures to respond to operational events and verify their effectiveness in supporting business needs. The operations department also collects metrics used to measure the achievement of desired business outcomes.
Everything keeps changing – your business context, priorities, and customer needs. It is important to design operations to evolve in response to change and to consider lessons learned through implementation.
Security. The concept of security includes the ability to protect data, systems, and assets by using cloud technologies to improve security. Security design principles: There are seven design principles for cloud security:
- Implementation of a strong identification foundation
- Ensuring traceability
- Applying security at all levels
- Automate security best practices
- Data protection during transmission and storage
- Preventing people from accessing data
- Preparation for dangerous events
Best practices: Before you design any workload, you need to establish security-affecting practices. There is a need to control who can do what. In addition, you must be able to detect security breaches, protect systems and services, and ensure data privacy and integrity through data protection.
You should have a clearly defined and practiced security breach response process. These tools and techniques are important because they support goals such as preventing financial losses or meeting regulatory requirements.
Shared Responsibility Model: AWS enables cloud-based organizations to meet their security and compliance goals. Because AWS physically protects the infrastructure that supports our cloud services, as an AWS customer you can focus on using the services to achieve your own goals. AWS Cloud also provides greater access to security data and an automated approach to responding to security events.
The concept of reliability. The term includes the ability of a workload to perform its intended function correctly and consistently within a set time frame. This includes the ability to run and test a workload throughout its lifecycle.
Design Principles
There are five design principles for reliability in the cloud:
- Automatic failure recovery
- Testing recovery procedures
- Horizontal scaling to increase the availability of the overall workload
- Do not guess the capacity
- Change management through automation
Best Practices: Before building any system, basic requirements affecting reliability must be established. For example, you need to have sufficient network bandwidth for the data center. These requirements are sometimes not taken into account (because they go beyond the scope of an individual project). However, with AWS, most of the basic requirements are already taken care of or can be addressed if necessary.
The cloud is designed to be nearly limitless, so the onus is on AWS to meet the needs of sufficient network and computing power, giving it the ability to resize and allocate resources as needed.
A reliable workload starts with strategic design decisions for both software and infrastructure. User architecture choices will affect workload behavior across all six AWS Well-Architected pillars. To achieve reliability, you need to follow specific patterns, such as loosely coupled dependencies, graceful degradation of functionality, and retry limits.
Changes in the workload or its environment must be anticipated and accounted for to achieve reliable workload performance. Changes include those imposed on your workload, such as spikes in demand, as well as internal changes, such as feature deployments and security patches.
Productivity efficiency. The concept of performance efficiency includes the ability to use computing resources efficiently to meet system requirements and maintain that efficiency as demand changes and technology evolves. Design principles: There are five design principles for cloud performance efficiency:
- Use of advanced technologies
- Ability to be global
- Use of serverless architecture
- Frequent experiments
- Automation
Best Practices A data-driven approach to architecture with high performance is required. Data collection should be organized for all aspects of the architecture, from high-level design to resource type selection and configuration.
Regular analysis of previous elections allows you to use the constantly evolving AWS cloud. Monitoring allows users to be aware of any deviation from expected performance. You need to be prepared to make compromises in the architecture to improve performance, such as using compression or caching or reducing consistency requirements.
The optimal solution for a given workload can vary, and often solutions combine multiple approaches. AWS Well-Architected workloads use several solutions and capabilities to improve performance.
The concept of cost optimization includes the ability to run systems to deliver business value at the lowest possible cost. Design Principles There are five design principles for optimizing cost in the cloud:
- Implementation of financial management in the cloud
- Awareness of the consumption pattern
- Measurement of overall performance
- Saving money on undifferentiated hard work
- Cost analysis
The sustainability discipline deals with the long-term impact of your business activities on the environment, economy, and society. Design principles: There are six design principles for cloud resilience:
- Awareness of impact
- Establishing sustainability goals
- Maximum use of resources
- Anticipating and leveraging new, more efficient hardware and software offerings
- Use of managed services
- Reducing the negative impact of your cloud workload on the environment
Conclusions
In this essay, detailed analytical work was carried out on infrastructure scaling strategies for business development in the field of sportswear. Based on the conducted research, the following conclusions can be drawn:
- Infrastructure scaling is an important component of successful business development in the field of sportswear. Ensuring sufficient capacity, logistics capabilities, and quick response to changes in demand are key factors in competitiveness.
- Developing effective scaling strategies, such as vertical and horizontal scaling, cloud-based services, and auto-scaling, is an important challenge for sportswear businesses. Each of these strategies has its advantages and disadvantages, so the choice of strategy should be made based on the specific needs and capabilities of the enterprise.
Factors influencing the need to scale infrastructure include demand growth, seasonality, geographic distribution of customers, and logistics. Taking these factors into account in scaling strategies will allow businesses to improve their performance in response to market volatility and meet customer needs.
Technological progress, in particular the use of cloud technologies, process automation and artificial intelligence, opens up new opportunities for effective scaling of infrastructure in the field of sportswear. Implementing these innovative solutions can help businesses increase the efficiency of their operations and improve customer service.
Successful infrastructure scaling in sportswear requires a systems approach where business management, technology, logistics, and marketing work together to develop and implement scaling strategies.
In general, the development and implementation of effective strategies for scaling infrastructure in the field of sportswear determines the success of enterprises in this field. The correct choice of strategies, taking into account influencing factors and the use of modern technologies will help enterprises to ensure sustainable development, competitiveness, and satisfaction of the needs of sportswear consumers.
References
- Informational Infrastructure – Wikipedia, Available at : https://goo.gl/9L7xCN
- O. Modlo The use of desktop programs in the cloud environment / E. O. Modlo // Cloud technologies in education: materials of the All-Ukrainian scientific and methodical Internet seminar (Kryvyi Rih – Kyiv – Cherkasy – Kharkiv, December 21, 2018) – Kryvyi Rih: Publishing Department of KMI, 2018. – 39 p.
- What is IT Infrastructure? com 2023 – Available at: https://www.ibm.com/topics/infrastructure
- Cohn, M. Agile Project Management with Scrum: Addison-Wesley Signature Series. – Boston: Addison-Wesley Professional, 2010. – 504 p.
- Kim, G., Debois, P., Willis, J., & Humble, J. DevOps Handbook: How to Create World-Class Agility, Reliability, and Security in Technology Organizations. – Portland: IT Revolution Press, 2016. – 480 p.
- O. M. Turavinina Cloud technologies of education in the system of information and communication technologies for educational purpose / O. M. Turavinina // Cloud technologies in education: materials of the All-Ukrainian scientific and methodical Internet seminar (Kryvyi Rih – Kyiv – Cherkasy – Kharkiv, 21 December 2012). – Kryvyi Rih: Publishing Department of KMI, 2012. – 9 p. 7. Chorna O. V. World trends in the development of cloud technologies / O. V. Chorna, N. A. Kharajyan, S. V. Shokalyuk, N. V. Moiseyenko / Theory and methodology of electronic learning. – Kryvyi Rih: Publishing Department of KMI. – 2013. – Volume IV. – p. 272-284.
- Apache CloudStack: Open Source Cloud Computing / Apache CloudStack. – 2014. – Available at : http://cloudstack.apache.org/
- Zhuravlyova I.V., Ogurtsov V.V. Organization of the information network infrastructure of the management of the territorial administrative unit (TAO) in the environment of “electronic government” // Zb.nauk.pr. Ukrainian Academy of Public Administration under the President of Ukraine. — Kharkiv: UADU, 2001. — Part 2. — P. 108 — 112.
- Humble, J., & Farley D./ Continuous Delivery: Reliable Software Releases through Build, Test, and Deployment Automation. – Boston: Addison-Wesley Professional, 2010. – p. 512
- Dombrowski, S. / The DevOps Adoption Playbook: A Guide to Adopting DevOps in a Multi-Speed IT Enterprise / Portland: IT Revolution Press, 2017. – p. 204 .
- Abbott, M., & Fisher, /M. The Art of Scalability: Scalable Web Architecture, Processes, and Organizations for the Modern Enterprise/ Sebastopol: O’Reilly Media, 2019. – p. 368 .
- Beyer, B., Jones, C., Petoff, J., & Murphy, N./ Site Reliability Engineering: How Google Runs Production Systems – Sebastopol: O’Reilly Media, 2016. – p. 552 .
- Forsgren, N., Humble, J., & Kim, G. Accelerate/ The Science of Lean Software and DevOps: Building and Scaling High Performing Technology Organizations – Portland: IT Revolution Press, 2018. – 288 p.
- Nygard, M.T./ Release It!: Design and Deploy Production-Ready Software – Dallas: The Pragmatic Programmers, 2018. – 376 p.
- Humble, J., & Farley, D./ Cloud Native DevOps with Kubernetes: Building, Deploying, and Scaling Modern Applications in the Cloud – Sebastopol: O’Reilly Media, 2017. – 372 p.
- Newman, S. /Building Microservices: Designing Fine-Grained Systems – Sebastopol: O’Reilly Media, 2015. – P. 280.
- Humble, J., Molesky, J., & O’Reilly, B. Lean/ Enterprise: How High-Performance Organizations Innovate at Scale, O’Reilly Media, 2015. – P.352.
- Vertical vs. horizontal scaling: what’s the difference and which is better , Available at: https://www.cockroachlabs.com/blog/vertical-scaling-vs-horizontal-scaling/
- AWS Well-Architected / Amazon 2023 – Available at: https://aws.amazon.com/architecture/well-architected/?wa-lens-whitepapers.sort-by=item.additionalFields.sortDate&wa-lens-whitepapers.sort-order=desc&wa-guidance-whitepapers.sort-by=item.additionalFields.sortDate&wa-guidance-whitepapers.sort-order=desc
- Vertical Scaling and Horizontal Scaling in AWS / com 2023 – Available at: https://dzone.com/articles/vertical-scaling-and-horizontal-scaling-in-aws
- Steps to Assemble the Right Infrastructure Building Blocks to Successfully Scale Your Business – Available at: https://www.entrepreneur.com/growing-a-business/how-to-build-the-infrastructure-needed-to-scale-your-company/438387